
Autonomous Machine for Inspecting Gas & Operations (AMIGO)
Summary
As a part of the AMIGO project, I...
➤ developed an anomaly searching control algorithm,
➤ trained custom RL policies in Isaac Lab,
➤ wrote a ROS2 based RL deployment framework,
➤ wrote additional ROS2 functionalities (actions, services), and
➤ supported our rapid prototyping efforts.
The goal was (and is) to develop an autonomous robotic platform for powerplant diagnostics. We outfitted the Unitree Go2 EDU quadruped with ...
➤ Jetson AGX Orin,
➤ 2D LiDAR,
➤ ZED X camera,
➤ RealSense camera,
➤ Raspberry Pi, and
➤ gas sensors.
With our additions, the robot could currently autonomously navigate indoors, leveraging our custom Nav2 implementation amigo_ros2. The team at EPPL are currently adding outdoor (GPS) functionality.

RL Locomotion Training and Deployment
Powerplants often exhibit difficult terrain for a quadruped to traverse. Specifically, most plants are littered with open-backed staircases that pose a great challenge for blind locomotion policies and controllers. Too often, the robot (especially smaller quadrupeds like the Go2) steps into the open region and falls face first into the stairs.
To tackle this issue, I acquainted myself with RL methods for robot locomotion. Starting from the basic Isaac Lab Go2 environment, I edited the reward structure, added privileged observations (for asymmetric Actor Critic NNs), implemented increased domain randomization, and abused my gaming laptop's GPU. To my surprise, once I had a policy that looked ~acceptable~ in the sim, I couldn't find a deployment framework for the Go2. So, I had to make my own and called it go2_rl_ws.
After a couple sketchy tests (where we hung the AMIGO up with paracord), it worked! Much to my disappointment though, the sim2real transfer wasn't exactly one to one... In fact, even with strenuous efforts in reward tuning, my policies reliably failed when deployed on the real robot. There are a few reasons why this was the case:
➤ Inconsistencies between the sim's motor models and those on the robot
➤ Inconsistent frequencies induced by the ROS2 deployment
➤ PD gain mismatches induced by the ROS2 deployment
➤ Overfitting of the sim's simulated dynamics
Using the blind locomotion standard, the following observations were used for the policy:
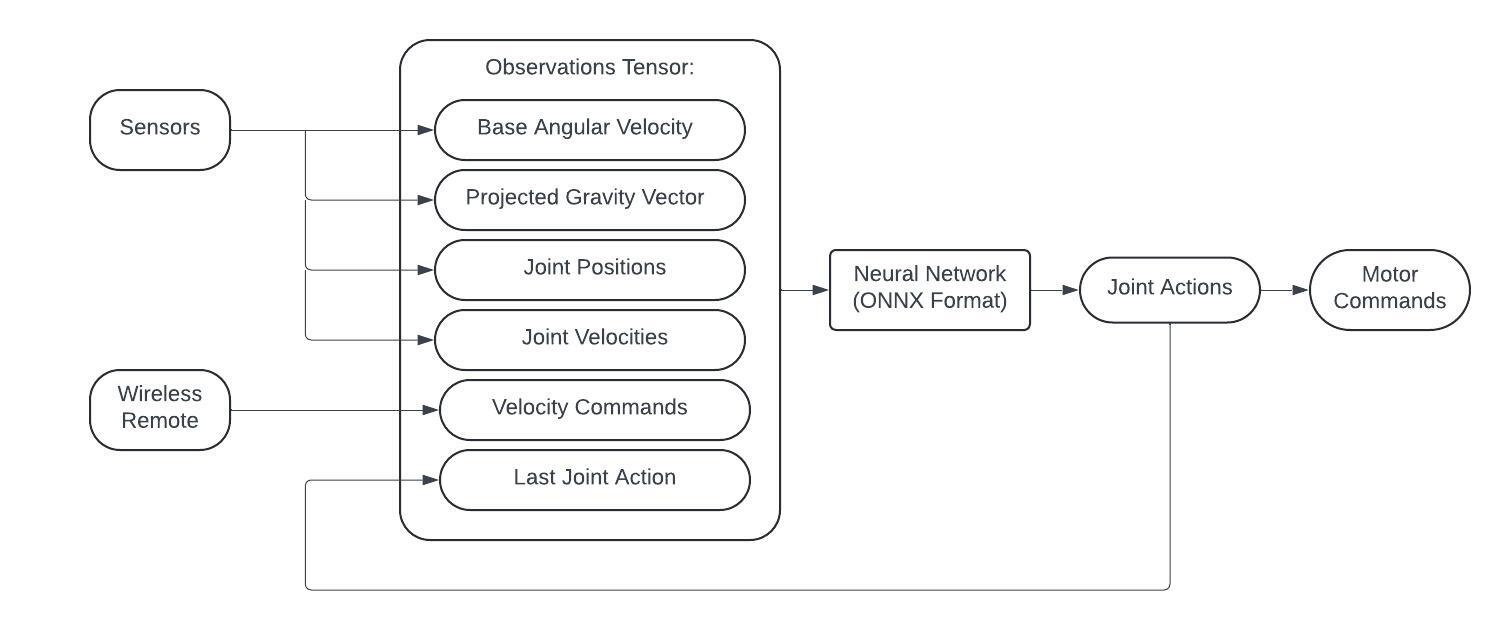
Despite the shortcomings, however, I was able to train and deploy a high frequency hopping gait. Here's what that looked like:
Anomaly Searching
Last semester, we began tackling autonomous room searching. This will be an invaluable asset during real-world deployment, allowing us to find anomalies in dynamically changing environments. My current approach assigns a time-dependant probability distribution to the region of interest, while the robot determines the next target waypoint in a roughly random manner. The idea is to "push" the AMIGO towards the higher probability areas, while not forgetting about lower probability areas.
The probability distribution is currently updated as follows, all starting with a uniform distribution, \(p_{0}(x, y) = 0.5\). $$ p_{t+1}(x, y) = p_t(x, y) + \alpha \left( \frac{\partial p}{\partial s} + \frac{\partial p}{\partial a} \right) $$ Where \(s\) is the robot position, and \(a\) are detected anomalies in the search area, and their influence on the probability is designed as follows. $$ \frac{\partial p}{\partial s} = \frac{\min(p(x,y))}{\beta} \cdot \tanh \left( (r_{\text{cam}} \cdot s)^2 \right) - \frac{\min(p(x,y))}{\beta} $$ $$ \frac{\partial p}{\partial a} = \sum_{i=1}^{N} \exp\left(-\frac{d_{\text{a}_i}}{r_a}\right) $$ Determining the next action at each time step is the true crux of this controller and still under development. We are looking to integrate principles of RL, while being able to learn while deployed.
Attributions
Funded by Steam Solutions, and housed by the Engineering Physics Propulsion Lab @ ERAU. Our custom Nav2 implementation, mostly authored by my colleague, Jose Castelblanco, can be found here.